A plan for Multi-Byte Unicode Character Support in GNU coreutils
Introduction
coreutils is the project that implements about 100 of the most well known and used utilities on any GNU/Linux system. These utilities are used interactively, or extensively in other programs and scripts, and are integral to the standard Linux server distros used today. Originally these utilities were implemented only considering ASCII or sometimes implicitly other unibyte character sets, but many of the assumptions break down in the presence of multi-byte encodings. As time has gone on this has become more of an issue as this graph representing the rise of UTF-8 use on the web indicates.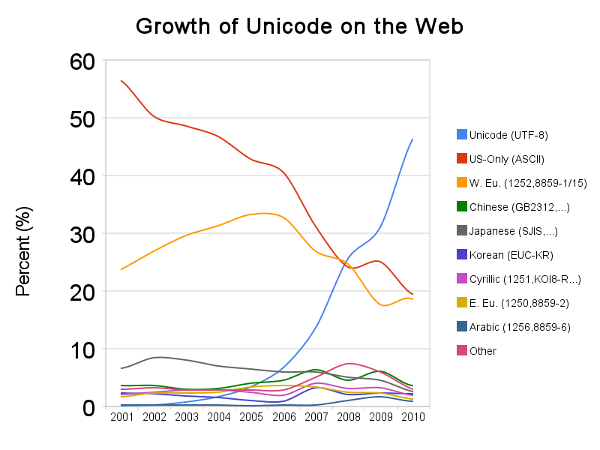
The obvious trend continues as can be seen in W3tech's more up to date stats
There is some support for multi-byte encodings which is detailed below, but it’s incomplete, has bad performance characteristics in most cases, has no tests, and has had many bugs and security issues. Having general support for all or even the most popular encodings in use will improve the performance, security and more importantly the reusablilty of these core components, which will help avoid reimplementations in other parts of the system with associated maintenance and security overhead.
History
There is already some support for multi-byte encodings in some distros such as Fedora, RHEL and SUSE, but interestingly not on debian or ubuntu. Also this patch has not been accepted upstream as it is largely a mechanical replacement and duplication of code without care and attention to the needs of the tool itself and its relation to multi-byte encodings. BTW an improvement that could be made independently to this multi-byte patch would be to provide history in git somewhere, as currently it’s just maintained as a large iterated patch.To test if the current patch is applied, you can try this basic operation:
fedora> printf '%s\n' útf8 | cut -c1 ú debian> printf '%s\n' útf8 | cut -c1 �The existing patch originated in the LI18NUX2000 effort and has been carried in Red Hat distros at least since 2001, and in SUSE distros. In 2001 there were discussions upstream between Paul Eggert, Jim Meyering and Bruno Haible about a more appropriate and considered approach, though more involved changes were not completed due to the size of the work involved.
Issues with the LI18NUX patch
- Not upstream
- Not standard across all distros
- Not used on debian based distros
- Ongoing maintenance overhead
- Started off as 2.7K line change to 10 files, but now is a 3.2K patch to 20 files
- There is no repository for the patch, so code changes are difficult to track
- Recent changes tracked at https://github.com/pixelb/coreutils/commits/i18n
- Regressions are easy to introduce, and have been
- Security
- Performance
- https://bugzilla.redhat.com/499220
- This was resolved just for cut, though as a patch to the LI18NUX patch and thus not a long term solution and misses out on detailed upstream performance work, like the near quadrupling of speed in cut in this recent patch set:
- https://bugzilla.redhat.com/499220
- uniq efficient multi-byte prototype
- This details some of the performance and to a lesser extent the functionality issues with uniq, and proposes an alternate uniq implementation with much better performance characteristics (sometimes up to 100x better).
- Incomplete
- It focused on mechanical adjustments to various text processing routines
- Some glaring issues like case folding in sort. The following works without -f
- printf '%s\n' 'ab' 'ác' 'ad' | LC_ALL=en_US.UTF-8 sort -f
- Avoided some “hard” issues altogether, like tr for example
- Has minimal tests
Upstream direction
The more considered approach mentioned above was to use a shared library to provide various unicode and character encoding functionality for use primarily by GNU coreutils, but usable by many others. A shared library was decided on due to the large amount of data required to represent various unicode tables etc. Since this is a large effort it languished a bit due to lack of resources, but Bruno Haible released libunistring in 2009. Some projects have since used it, like libidn, and there was an initial prototype done with the join utility in coreutils in 2010, but that again floundered due to lack of time. join(1) was a good first choice in regard to testing out various functionality that any of the coreutils might need, but turned out to be a bad first choice in retrospect due to the interdependence with the sort(1) and uniq(1) utilities which need to process and compare data cohesively.An implementation plan
- Top level goals
- Implement at least the functionality provided by the existing LI18NUX patch so that it can be dropped in favor of upstream code
- Improve on the many gaps and issues with the LI18NUX patch
- Identify implementation constraints
- Do we normalize within each util or rely on external tools like iconv and uconv
- How do we handle invalid encodings; substitution, elision, leaving in place?
- Do we support all encodings
- Do we prefer some encodings
- There is the argument for adding UTF8 specific routines at least
- Do we support all case transformations
- For example titlecase letter 'Lj' (U+01C8) is neither upper or lower but does have an upper case (U+01C7)
- Do we support extra functionality like transformed comparisons (a=á, 🅐=A, …)
- Do we support comparisons against more than the primary weight
- For example: printf '%b\n' '\u2461' '\u2460' '\u2461' | sort | tr -d '\n' gives ② ① ②
- Where do we draw the line with all the unicode and encoding corner cases
- replace control chars in df output, which is not compatible with all encodings but is an acceptable tradeoff. This is an example where ostensibly encoding agnostic tools are impacted.
- There are many combinations to test and a significant proportion of the work
- There are essentially no tests in the current i18n patch
- There may be some distro tests that could be provided
- There are some LSB tests we might leverage
- There is a large advantage in that most utilities are independent and i18n support can be landed in stages, and correspondingly the LI18NUX patch can be reduced in stages.
- many of the “fileutils” are not impacted
- some are easy to adjust so we should start with these
- expand, …
- some are more involved
- tr, ...
- while some are interdependent
- sort, uniq, join
- These are also hard as they support field matching, collation, delimiter searching, and subset field output.
- sort, uniq, join
- To remove the existing patch the order would probably be
- expand, unexpand, fold, cut, pr, (join, sort, uniq)
- depends on the function of the tool. Sorting, searching, indexing, comparing,...
- For example, uniq may only care that adjacent lines differ rather than the much more expensive task of determining an order
- I.E. do we use an internal UTF8 representation, or a fixed width internal encoding
- buffering and searching optimizations you can use for UTF-8
- Note wchar_t is only 16 bits on windows, though gnulib supports char32_t
- performance characteristics of UTF8 decoders
- Ensure performance in “C” locale is maintained
- libunistring shared lib used so that tables are shared between all tools
- for example we have to jump through a few hoops to not link printf with libunistring as otherwise a 16% startup overhead is incurred for this short running util.
- libunistring implementation tradeoffs and profiling
Time estimates
- 2 weeks planning/investigation
- implement shared field implementation for sort, join, uniq: 2 weeks
- Initial patch from Assaf Gordon needs to be upstreamed
- Do this first so subsequent multi-byte adjustments can be shared
- implementation and test for tools in existing i18n patch
- expand, unexpand:
1.5 week - fold:
0.5 week- maybe add unicode line breaking: 1 week (using gnulib's unilbrk/)
- cut:
1 week - pr: 1 week
- join:
1 week - sort: 2 weeks
- uniq:
1 week (see uniq prototype above)
- expand, unexpand:
- other tools (ordered by priority)
© Mar 16 2015